

Elsa Konieczynski
MS Candidate, Nutrition Epidemiology and Data Science, Friedman School of Nutrition Science and Policy, Tufts University
I am entering my final year as a master’s student in the Nutrition, Epidemiology, and Data Science program at the Friedman School. I also work in the Bone Metabolism Laboratory at the HNRCA, where I support clinical trials related to nutritional interventions and muscle strength in older adults. These experiences have helped me to realize my research interests in the relationship between nutritional and social exposures with musculoskeletal health across the lifecourse. In the future, I hope to explore these interests through further training in epidemiology, with the ultimate goal of contributing to a healthier and more equitable world for people as they age.
Final Presentation
Final Project
AI-Powered Identification of Ultra-Processed Foods
Project Description
Abstract: Ultra-processed food (UPF) has become a central focus of recent nutrition literature. The NOVA framework is the most widely used classification system for categorizing UPFs, but interpretations vary. The tool proposed in this use study will address this issue by implementing an objective and standard method for identifying UPFs. By utilizing natural language processing, the tool will be able to identify UPFs in the food databases by the presence of non-culinary ingredients or cosmetic additives. Expected outcomes include a standardized approach to identifying UPFs. This methodological consistency will advance research efforts to study UPFs and their relationship with human health.
Introduction and Rationale:
Context and Background
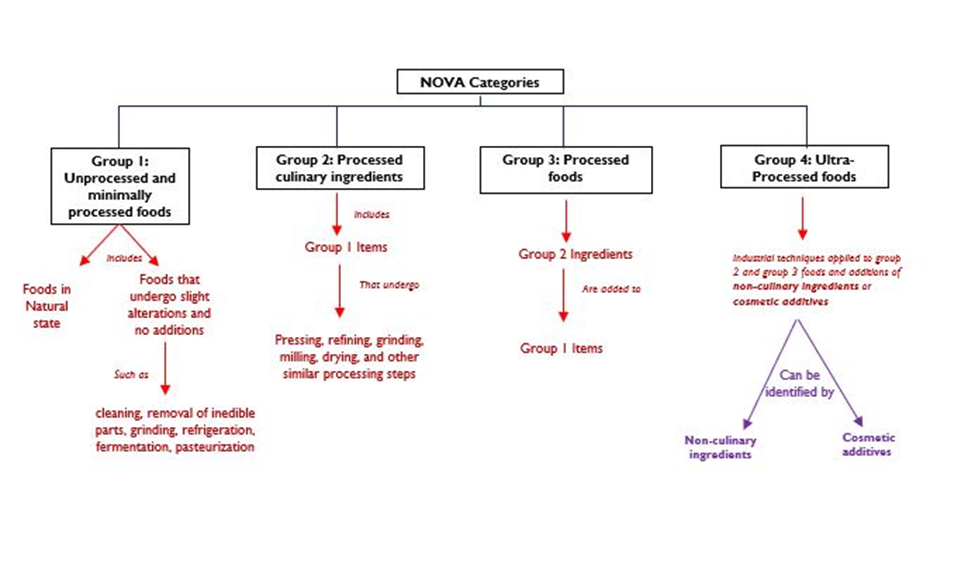
Ultra-processed foods (UPFs) have garnered significant attention in recent years due to accumulating evidence linking it to various adverse health outcomes. The NOVA system, developed by researchers at the University of São Paulo in Brazil, is a widely adopted framework for identifying ultra-processed food (1). There are four food categories (groups) in the NOVA framework: unprocessed or minimally processed foods (Group 1), processed culinary ingredients (Group 2), processed Foods (Group 3), and ultra-processed foods – also known as UPFs – (Group 4).
According to the NOVA framework, UPFs are defined as “formulations of ingredients, mostly of exclusive industrial use, that result from a sequence of industrial processes (1).” They are described as foods that are designed to be convenient, highly palatable, and have a long shelf life. They contain cosmetic additives and non-culinary ingredients designed to mimic sensory qualities of unprocessed foods or enhance palatability. Examples include packaged snacks, frozen meals, sugary beverages, and many ready-to-eat products. UPFs are a health concern because they are typically high in added sugars, sodium, unhealthy fats, and lack beneficial nutrients like fiber, vitamins, and minerals found in minimally processed foods (2).
Ultra-processed foods have become a central topic in nutrition literature due to a growing number of publications that identify an inverse relationship between UPF consumption and health. For example, A 2020 systematic review of 23 observational studies on ultra-processed food intake and health outcomes found that higher consumption of ultra-processed foods was associated with increased risks of overweight/obesity, dyslipidemia, metabolic syndrome, cardiovascular disease, cerebrovascular disease, depression, and higher all-cause mortality in both cross-sectional and prospective cohort analyses (3).
Despite the growing number of publications on ultra-processed foods, the lack of standardized methods for classifying ultra-processed foods has been a major limitation in evaluating the relationship between UPFs and health. One of the key challenges lies in the subjective nature of evaluating ingredient lists and determining whether a food item meets the criteria for being classified as ultra-processed. A recent study surveyed French food and nutrition specialists and asked them to assign food products with and without ingredient information to NOVA categories. Results showed that experts assigned foods to NOVA groups with low overall consistency even when ingredient information was available (Fleiss’ κ was 0.32 and 0.34 for the foods with ingredients list (n = 159 evaluators) and foods without ingredient lists (n = 177 evaluators), respectively) (4). Overall, without a consistent approach, researchers classify foods differently, making it difficult to draw reliable conclusions about the relationship between ultra-processed food consumption and various health risks. A lack of consistent definition also makes it difficult to construct policy regulating the manufacturing or sale of ultra-processed foods, if such policy is warranted by consistent research on UPFs and health in the future (5). Finally, the individual approach to classification via manual assignment is time consuming and labor intensive.
To address these challenges, this project aims to develop and validate an AI-driven tool that can objectively classify UPFs in food databases by detecting the presence of non-culinary ingredients and cosmetic additives. By leveraging natural language processing techniques, the tool seeks to provide a standardized approach to UPF identification, facilitating more rigorous and comparable research in this field.
Objective(s) of the use case:
The objective is to create a standardized and objective approach to identifying ultra-processed foods (UPFs) based on their ingredient composition.
Methodology/Approach:
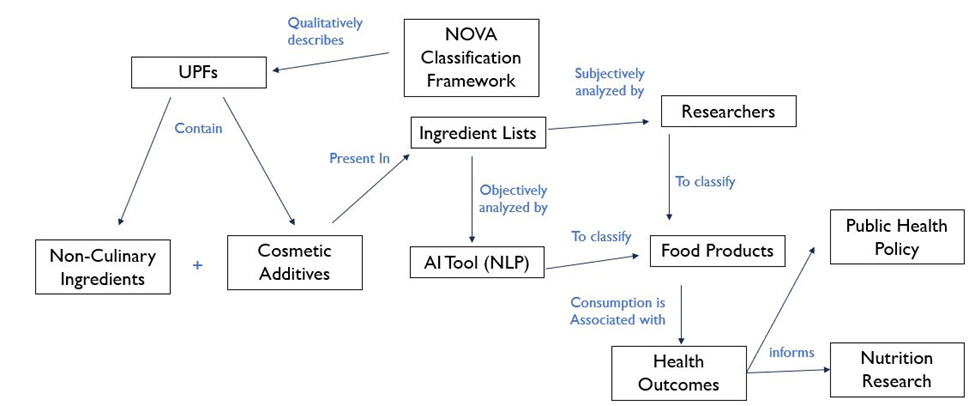
The proposed methodology involves leveraging natural language processing (NLP) techniques to analyze ingredient lists of food products and detect the presence of non-culinary ingredients and cosmetic additives, as ‘markers’ of high levels of industrial processing. The presence of such additives and ingredients are unique to ultra-processed foods according to the NOVA framework (1). Specifically, the approach would involve the following steps:
- Compile a comprehensive list of known food additives and non-culinary ingredients from authoritative sources like the FDA’s database of approved food additives, the Codex Alimentarius list of food additives, and other relevant databases.
- Named entity recognition (NER) models will be trained on the compiled list of cosmetic additives and non-culinary ingredients to accurately recognize them in text.
- The NER models will be used to automatically identify cosmetic additive and non-culinary ingredient names from ingredient lists in food databases. Foods that contain any of these additives or ingredients will be classified as ultra-processed
- The list of additives will be continuously updated as the food industry introduces new formulations and ingredients.
Key stakeholders involved:
- Nutrition researchers and public health organizations interested in studying the health effects of ultra-processed foods.
- Food manufacturers and regulatory bodies seeking to understand and potentially label the degree of processing in their products.
- Consumers and advocacy groups concerned about the prevalence of ultra-processed foods in modern diets.
Proposed AI techniques or tools:
The primary AI technique proposed is natural language processing (NLP), which would be used to analyze ingredient lists and detect the presence of specific markers of industrial processing, such as non-culinary ingredients and cosmetic additives.
Knowledge Graphs
This knowledge graph shows relationships between the four NOVA groups and their component parts. The ultra-processed food section informs the methods for my use case.
Conceptual/Causal Diagrams:
This conceptual diagram shows the relationship between the tool proposed by my use case and nutrition research on ultra-processed foods
Ethical Considerations:
In developing AI tools to classify foods as ultra-processed or not, human-centric design is a crucial ethical consideration. There is often a conflation between a food’s processing category and its perceived healthiness. Developers must transparently communicate the many limitations of the methodology in this use case, which does not take into account the type of cosmetic additive or non-culinary ingredient, the amount of such ingredients, or the available evidence relating any such given ingredient to human health. The tool is not intended to be used to inform consumer decision making on food choice and nutrition and is instead a research tool for further investigation into the utility of the NOVA framework, and the relationship between food processing and health. Clear guidelines for interpreting the classifications set forth by the proposed AI tool should be provided to both researchers and the general public to avoid misunderstandings.
Secondly, the composition of the list of ultra-processed food ‘ingredient markers’ raises ethical concerns. Non-culinary ingredients differ across cultures – it would be important to ensure the list of markers would not label ingredients not typically used in the developer’s culture, but used regularly elsewhere, as ‘non-culinary ingredients’. Additionally, the list of ‘ingredient markers’ would need to be continuously updated according to changes in manufacturing ingredients to be useful.
Conclusion and Recommendations:
Despite the tool’s strength in addressing a need for objective UPF classification in the nutrition community, it is not without limitations which should inform its implementation – these include:
- Reliance on pre-defined list of non-culinary ingredients and cosmetic additives – If the list is not comprehensive, or updated continuously, the tool will not comprehensively identify UPFs
- Binary classification approach (UPF or non-UPF) – this will inevitably oversimplify the spectrum of food processing levels and also overlooks the wide differences additives/non-culinary ingredients in terms of their impact on human health
- The ingredient markers are derived from the NOVA description of UPFs – therefore, the proposed classification method has all of the limitations inherent in the NOVA framework, including the lack of nutritional context of the food processing
Ultimately, this use case proposes an AI tool that is a useful, though limited, first step in objectively classifying ultra-processed foods. The tool would address a current critical issue in nutrition research – the subjective and labor-intensive process of classifying ultra-processed foods – by providing a standard and objective method. A future research direction utilizing this tool could be to re-analyze studies that looked at the relationship between UPF consumption and health outcomes, but with the standard classification scheme for UPFs. Another would be to expand on the sophistication of the tool to investigate the potential impact of ingredient order and quantity on the classification of UPFs.
References
1. Monteiro CA, Cannon G, Levy RB, Moubarac J-C, Louzada ML, Rauber F, Khandpur N, Cediel G, Neri D, Martinez-Steele E, et al. Ultra-processed foods: what they are and how to identify them. Public Health Nutr 2019;22:936–41.
2. Monteiro CA, Cannon G, Moubarac J-C, Levy RB, Louzada MLC, Jaime PC. The UN Decade of Nutrition, the NOVA food classification and the trouble with ultra-processing. Public Health Nutr 2018;21:5–17.
3. Pagliai G, Dinu M, Madarena MP, Bonaccio M, Iacoviello L, Sofi F. Consumption of ultra-processed foods and health status: a systematic review and meta-analysis. Br J Nutr 2021;125:308–18.
4. Braesco V, Souchon I, Sauvant P, Haurogné T, Maillot M, Féart C, Darmon N. Ultra-processed foods: how functional is the NOVA system? Eur J Clin Nutr 2022;76:1245–53.
5. Gibney MJ. Ultra-Processed Foods: Definitions and Policy Issues. Curr Dev Nutr 2019;3:nzy077.
Hi Elsa,
I enjoyed your presentation. Your work could significantly improve the consistency and reliability of studies on UPFs and health. I look forward to seeing how this standardized approach of objectively identifying UPFs will influence further studies and policies.
This is a very interesting use case as many food companies will look at the nutrition facts panel + ingredients statement of competitor/reference products in the market, then attempt to make a “better-for-you” version. This could help in making minimally processed versions of products in the market.
This is a really interesting use case Elsa,
Let’s take a second to think specifically about artificial, alcohol-based sweeteners, and other added sugars. I can only imagine the implications of not only having an up-to-date ontologocial database that can identify not only UPFs from non-UPFs, but also a database that includes all of the variations for many of these added sugars, etc. I am excited to see where your research takes you!
Hi Elsa! I really, really like how your project evolved. I am curious as to what you would use to identify the risk of the cosmetic additives? I feel like there is an unmet need to have the cosmetic additives ranked in some way to identify their potential health risk. Would you first start in the US or what would be your use case? I am also curious if you would use existing data to identify the category of UPF to start with. I know soda is a large contributer to intake but so are commercially produced baked goods. This would also be a great next step to your fantastic research!
Hi Elsa, this project is very fascinating! I’m curious about how you will handle the challenge of continuously updating the database of additives, considering the rapid pace at which new ingredients are introduced into the market and how will you ensure the NER model’s adaptability to new data without frequent retraining.
Hi Elsa, I really hope that you continue this work (future PhD?!)! I believe that a systematic review on UPFs classification methodology would be a fantastic contribution to the research knowledge set. Beyond that, you’ve laid out the need for utilizing NLP to identify UPFs very well. I am excited for your next steps with this!
Hi Elsa, your proposed project sounds very interesting since many people use NOVA, but the classification is still very complicated. I’m curious about how, given the variability and complexity of ingredient lists, your AI model adapts to regional variations in food formulations.
Hello Elsa, Thank you so much for your work here. You can tell how passionate you are about NOVA and UPF. There is so much confusion in this area that I can only imagine how valuable this work will be at creating consistency within the field. The future implications from a consumer to nutritional/health research and policy development are endless. Well done!