
Cache contention is the result of multiple occupants (cores, processes, workloads, etc) having a cache in common. Growing cache needs and demand for scaling/multitasking couple to make cache contention a fixture and indeed a feature of modern processing. However, evaluating workloads and architectures in this context is complicated by 2 things: diverse workload run-times; and the exponentially growing time to run > 1 workload at a time.
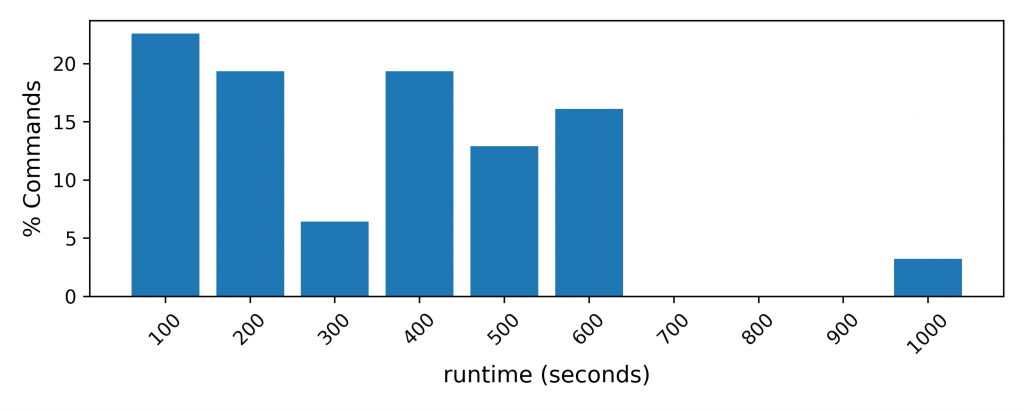
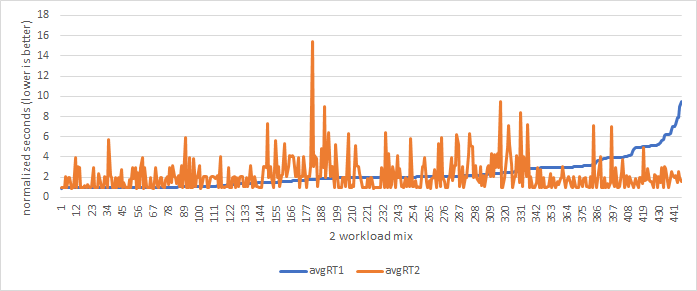
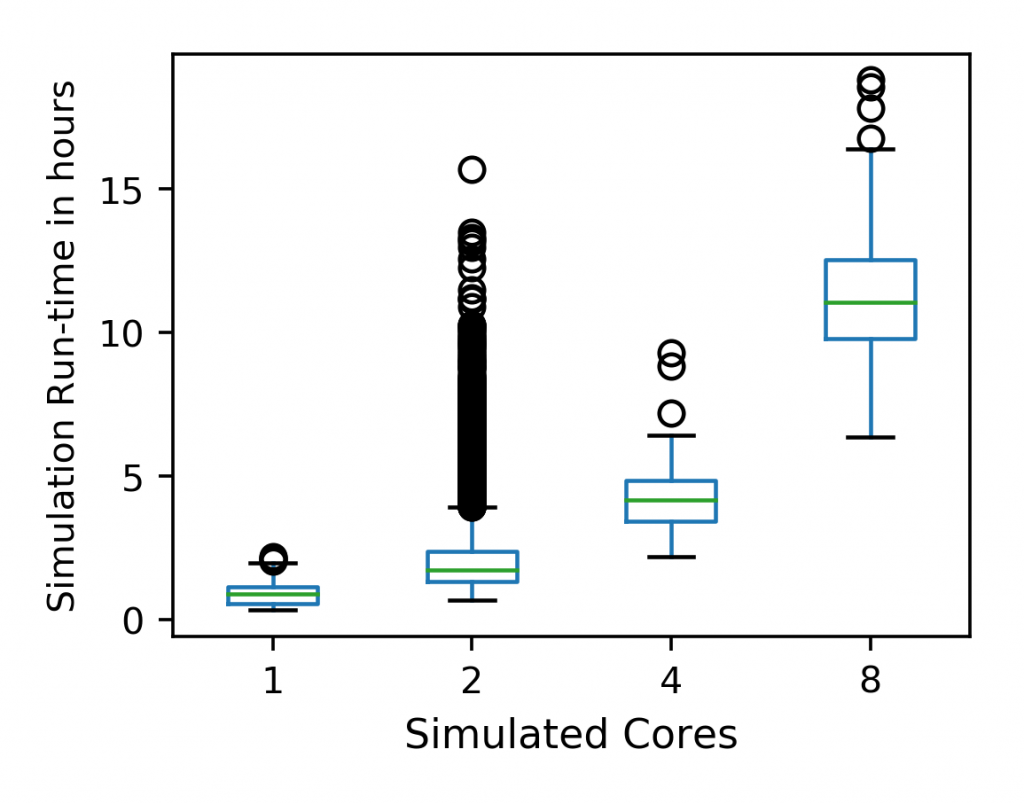
We observe simulation run-times vary in (1st figure) by as much as 14 minutes within the SPEC 17 rate sub-suite on an Intel Xeon Silver 4110 @ 2.10 GHz. When run together, we observe as much as a 16X increase in runtime for a given workload (2nd figure). Simulation results point in the 3rd figure demonstrates we have average run-time grows exponentially with additional cores, and simply adding a second workload to the simulation can have similar increases in runtime to scaling up to 4 and 8 cores!
Contention analysis frameworks often build a tunable workload to run alongside a workload of interest. The consequence of doing so requires the tunable workload to be tuned to a given system to uniformly fill each cache set with a certain number of blocks with some pattern. The consequence is similar to (if not worse than) adding a second workload. Additionally, fixing patterns increases the number of experiments for the sake of control.
We want a method that avoids the second-workload-runtime problem by letting the system induce cache contention via forced cache evictions through the replacement policy. The method should allow us to reduce the number of experiments and total time required to conduct a contention sweep. Further, we take advantage of the fact that locality is largely filtered out by the time data is placed in the last-level cache and accesses appear random. By doing so, we believe approximating induction as a random event with some probability is an appropriate proxy.