
Plokamos is a new text annotation framework developed by Frederik Baumgardt and the Perseids project. It is a browser-based tool that can be used to support scholars and students of literary disciplines in their work with text. Plokamos provides users with the ability to assign meaning to segments of text, to share their assertions with colleagues and classmates and to visualize the result of their work in aggregate. We have been using Plokamos as a plugin to our Nemo text browser in the classroom over the last 2-3 months and are looking forward to making it generally available to everyone for use on any source texts in early 2017.
Plokamos is really a continuation of our previous work in building a comprehensive toolset to enable our users to create and use semantically meaningful textual annotations. Our goal in this next step was to better integrate the individual components we used previously, to provide data validation assistance at annotation time, and to be in a better position to adapt our tools to new use cases. In the process we also wanted to make it easier for the users to enter data from a shared and controlled vocabulary. Furthermore, we aimed to add data versioning functionality to the infrastructure to follow students’ progress, to enable parallelism between text and annotations, and to provide this functionality as a tool for scholarly work. Finally, we planned for the application to be easily extensible to allow us to expand into more use cases over time as well as allow collaborators to tailor the annotations and the user interface to their own needs.
 Figure 1: Plokamos tooltip embedded into a web article
Figure 1: Plokamos tooltip embedded into a web article
In more technical terms, Plokamos is made up of an almost fully self-contained Javascript client application to be loaded inside a browser window, and a server-side linked-data named graph store with a SPARQL endpoint. In addition to annotation data, the quad store also serves configuration data that enables the client to validate, interpret and adequately visualize the annotations.
The Plokamos client consists of 3 layers which handle the annotations at different levels of abstraction and each layer provides its own mechanism to extend the application and use it for new kinds of sources, data types, forms of presentation or editing interfaces.
The annotator/applicator layer is the central piece of a Plokamos client application. It manages a local copy of the annotation data, adds interactive highlights to the source text and keeps a history of modified and newly created annotations. It has a core logic that is using SPARQL and the Open Annotation linked data framework to retrieve the available annotations and place them on their correct locations within the text. It can be extended to be able to handle different types of locations (“Selectors”) and different shapes of annotation payloads (“Annotation bodies”).
While the previous layer interprets annotations as just a network of entities and relations, and is agnostic to specific meaning (“Ontologies”) that is embedded in the network, the ontology layer is there to find and extract meaning from it. It can shape parts of the network into objects, translate URIs into easier to understand descriptions, and vice-versa. This is an essential step to negotiate between Plokamos’ general-purpose nature and its goal to provide user-friendly interactions. The ontology layer can be extended with new templates to extract objects from the graph and with additional dictionaries that provide translations between machine- and human-readable representations of the annotations.
The plugin layer takes the extracted objects and creates user interfaces for them which allow users to read and edit the data in different forms. Plugins can either let the ontology layer automatically select ontologies for the object conversion or specify them explicitly. The annotator/applicator layer provides placeholders for plugins to insert themselves into during Plokamos’ initialization, currently there are two such placeholders for annotations on phrases and whole documents, respectively. Inside the placeholders plugins can be designed freely using HTML and Javascript, including libraries such as Bootstrap and d3.js.
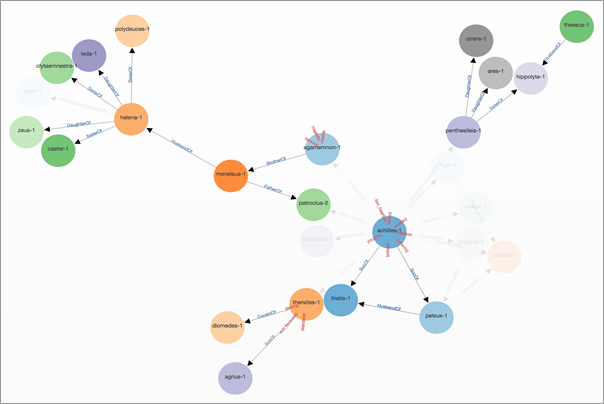
Figure 2: Visualization of corpus-level annotations filtered by family relationships
Over the course of the fall semester this architecture has proven itself to be useful and flexible for timely adaptations. We were able to develop new, unobtrusive and intuitive user interfaces for both the annotation reading and editing on single text passages as well as annotation visualization on a corpus. We also achieved our goal of improving the (syntactic) quality of the annotation data by providing the users with suggestions and visual feedback about the plausibility of the entered data. This last step benefited from the feedback that our students gave us while using the tool for their coursework and which we were able to quickly implement as additions to our plugins.
In 2017 we plan to focus on two particular features for Plokamos which we think will help make it a useful tool for many applications. The first one is a refactoring of the component in Plokamos that anchors annotations in their source data — the aforementioned Selectors — to enable higher-level annotations, i.e. annotating annotations. The obvious use case is for educators to grade and comment on their students annotations, but we’re sure that this will unlock further very interesting ways for scholars to express ideas. The second planned feature is the ability to run multiple instances of Plokamos on different regions of a website and let them interact to annotate relationships between segment of the regions. Those relationships can be for example assertions or translations, but again we’re convinced that this provides a foundation for new types of annotations that will emerge with time.
In addition to these features, we will round out the support for open, standards-based access to annotations created through Plokamos. First, we will add full API support, through an implementation of the RDA Collections API. Second, we will work towards updating the annotation data model as needed to be in compliance with the latest version of the Open Annotation specification, the Web Annotation data model.
We’re excited to watch Plokamos play its part as both a platform for data entry as well as experimentation with new kinds of scholarly concepts, as the Digital Humanities continue to reshape scholarship in the digital era.