
This project strives to answer the question, “what needs to be accelerated.” Figure 1 shows the result of characterizing workloads using Callgrind from Valgrind suite. It shows the distribution of execution time between standard libraries, such as stdb, glib, string, stdio; and user’s source code. Some kernels spend time mostly in the user’s source code, such as liblinear and PCA; while PCA and SVM-cif spend between 15-30% of their time in functions from string.h. Both standard libraries and user code should be inspected for similarities.

Figure 1: Acceleration opportunities in workloads.
We introduce Shared Accelerators to increase workload coverage of each accelerator. Each Shared Accelerator (SA) is a generic enough to cover more than one kernel and still accelerate each of the workloads that it covers. SAs compared to programmable arrays such as CGRAs, Dyser, and BERET: Shared Accelerators are designed to fill the gap between ASIC and more reconfigurable fabrics such as CGRAs. SAs’ average speedup is 2x faster than CGRAs; while normalized energy-per-task in SAs is on average 10x better than CGRAs. By targeting the similarities between workloads and not focusing only on computation and dataflow density of workloads, we minimize the communication and scheduling overhead.
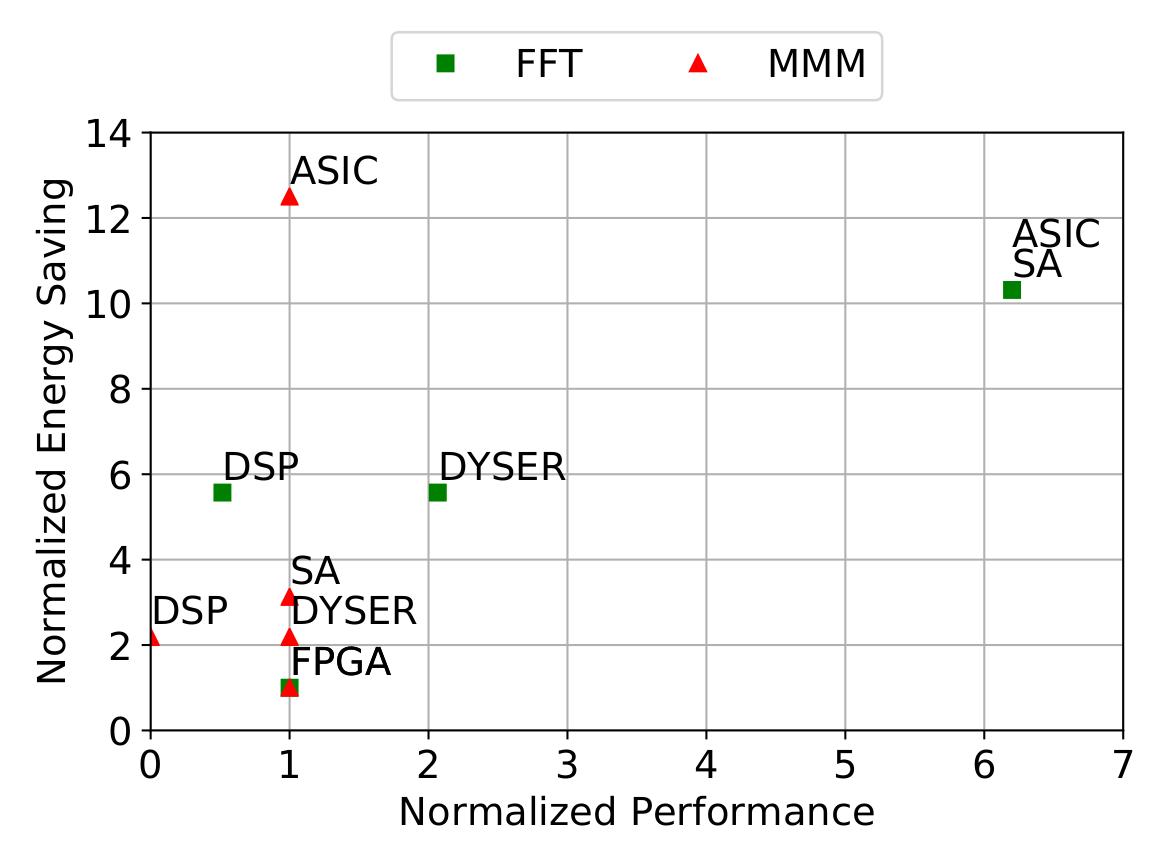
Two kernels FFT and Matrix Multiplication are compared in different frameworks. SAs performance for Matrix Multiplier is better than DSPs [Liang and Huang 2008] and the same as DySER (SIMD), FPGAs, and ASIC. However, SAs energy saving is only second to ASIC.


The structure for Dedicated Accelerator on top versus compared to Shared Accelerator on the bottom.