
With the end of transistor scaling, increased performance and energy-efficiency no longer comes solely from Moore’s law but instead from the intelligent customization and optimization of computing hardware for specific applications. Our research team has built tools to construct better accelerators,shared accelerators (SAs), that provide increased workload coverage with similar energy-efficiency of standalone application specific hardware (ASICs). The use of shared accelerators in a system could more than double the number of workloads that could execute efficiently with the same chip area. However,this is only possible if hardware-software systems are invented that can support shared accelerators. This project aims to build the automated EDA tools to identify shared accelerators and the system infrastructure necessary to invent new hardware interfaces, OS support, and language support for shared accelerators.
Specialized hardware accelerators are found in a range of chips from embedded systems to high perfor-mance systems. In fact, the recent mobile SoCs from Apple and Samsung have over a third of the chip areadedicated to hardware accelerators. These accelerators are often designed to execute a specific kerneltypically a standardized workload such as video decoding or encryption. Designers choosing to include spe-cialized hardware have to predict that hardware included will provide coverage for workloads that users ofthe device care about. If the designer guesses wrong, the hardware is left unused.
What is a Shared Accelerator ?
We introduce Shared Accelerators which can accelerate two or more kernels. A simplified example is shown in Figure 1,where a system with accelerators for two MachSuite bench-marks, BBGemmandTriad. Common hardware is identified from application source code, using our automated ReconfAST methodology. Covering multiple software kernels with the same piece of hardware is not new, there are accelerators in the image processing and signal processing domains that are parameterizable and capable of executing multiple standards. However, this methodology allows designers to identify similarities between very different workloads.

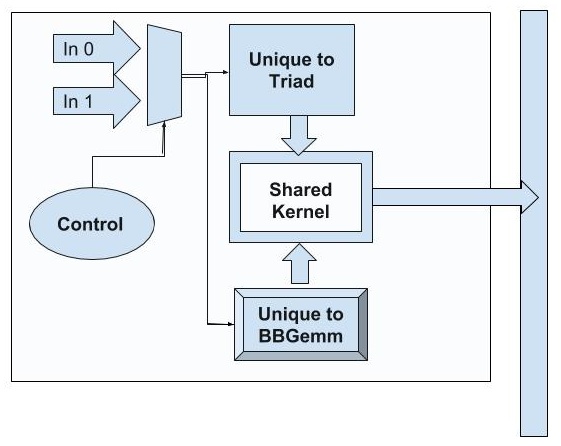
(a) Dedicated Accelerator (DA) (b) Shared Accelerator (SA)
Figure 1: Example System with Shared Accelerators. Instead of a dedicated accelerator for each kernel ((a) on left), shared accelerators ((b) on right) include all of the hardware for both kernels and common hardware kernels are automatically discovered and shared to reduce area.
By identifying similar control and arithmetic functions across applications, an SA can be designed for multiple kernels. ReconfAST, described in Figure 2, expresses each application with an annotated graph and finds the largest similar subtrees between applications using a sub-graph isomorphism algorithm. We devised a clustered AST (CAST) node library to replace software-based control structures with hardware implementable CAST nodes that adds constraints to the search and more accurately identifies similar kernels.
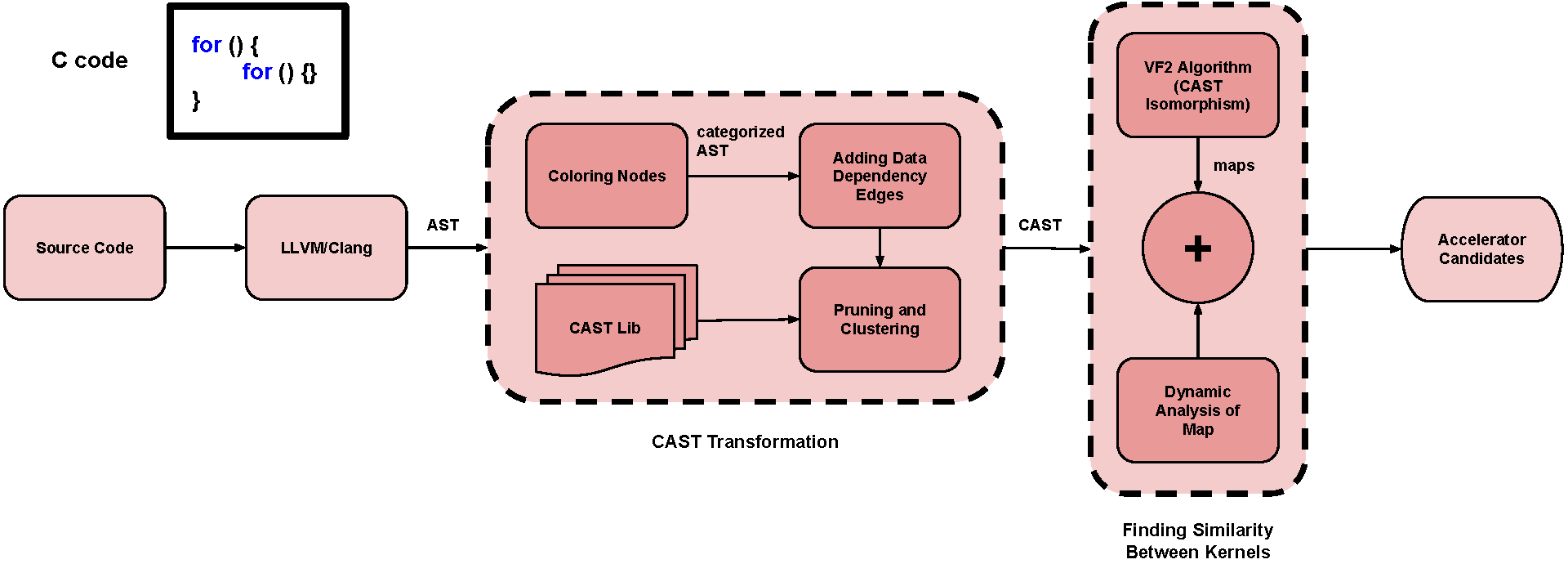
Figure 2: Block diagram of the ReconfAST methodology. Static ASTs are generated with LLVM-CLANG. Before comparing workloads, a pre-processing tool transforms the AST into a Clustered AST (CAST) by removing nodes not amenable to hardware and finding common AST patterns using the CAST library. Then candidate regions for shared hardware acceleration are identified using sub-graph isomorphism (VF2 algorithm).
The preliminary results of our tool are promising. ReconfAST can cover a large fraction of two workloads and the hardware is smaller than the cost of two hardware accelerators. We looked for shared accelerator candidates across all MachSuite benchmarks for accelerator systems, future work will include larger code bases for mobile and cloud workloads.
Future Work:
The details of the ReconfAST methodology are and experimental results are under review for a future publication. We are now investigating new workloads for Shared Accelerators, fast EDA methodologies, and the system implications for Shared Accelerators.
Shared accelerators must be supported by hardware and software systems for their potential to be realized. This includes the invention of hardware-software interfaces that support lightweight interactions with SAs. Because these accelerators will be a
shared resource between applications and threads, operating system support and hardware-aware scheduling algorithms are needed. Finally, programmers will need language support to utilize hardware accelerators and make it easy to iden- tify shared accelerators. Developing system support in each of these three research areas will be a multi-year research effort.
While building the infrastructure, a secondary goal of this eort is to study additional workloads for mobile and cloud computing. Most of the literature in many-accelerator systems use benchmark suites of small kernels. We focus this eort on accelerating edge applications for future high-performance mobile and embedded devices.
Funding:
“CAREER: Combating Dark Silicon through Specialization: Communication-Aware Tiled Many-Accelerator Architectures” 2/1/2014 – 1/31/2020. $470,000. National Science Foundation (NSF)
Publications:
- Parnian Mokri, Mark Hempstead, Improving HLS with Shared Accelerators: A Retrospective, Workshop on Languages, Tools, and Techniques for Accelerator Design (LATTE) 2021, April 16, [Video][Camera_Ready_Papaer][Latte21_FinalSlides)]
- Parnian Mokri, Mark Hempstead, Early-stage Automated Accelerator Identification Tool forEmbedded Systems with Limited Area, International Conference On Computer Aided Design (ICCAD) 2020, Nov 2 [video] [slides]
- Parnian Mokri and Mark Hempstead. “Early-stage Automated Identification Tool for Shared Accelerators” Poster Presentation. Field-Programmable Custom Computing Machines (FCCM2020), April 2020. [PDF] [Video]
- Parnian Mokri, Maziar AmirAski, Yuelin Liu, and Mark Hempstead. “Building Reconfigurable Shared Accelerators throughEarly-stage Automated Identification of Similar HardwareImplementations with Abstract Syntax Trees” Poster Presentation. International Symposium on Field-Programmable Gate Arrays (FPGA2020), Feburary 2020. [PDF]
- P. Mokri and M. Hempstead, “Fingerprinting Coarse-Grained Reconfigurable
Accelerators Using Data Movement and Structural Similarities in Applications” Boston Area Architecture Workshop (BARC), Jan. 2018. - P. Mokri and M. Hempstead, “ReconfASTs: Early-stage Identification of Reconfigurable Accelerators with Annotated Abstract Syntax Tree”, Boston Area Architecture (BARC) Workshop, January 2017.
- P. Mokri and M. Hempstead, “Stockpile Of Accelerators: A Methodology To Increase Accelerators’ Coverage”, Boston Area Architecture (BARC) Workshop, January 2016.