A lot of work continues to go on behind the scenes as we move to replace the current Perseus 4.0 (the Hopper). Our goal is to finish the transition by fall 2024, with new functionality folded into the Scaife Viewer until this can fully take the place of the now venerable system. Those who are more technically inclined can follow much of what is being done by tracking issues on the Beyond Translation Github site.
New functionality includes support for new kinds of annotations such as treebanks, translations aligned at the word and phrase level, automatic mapping, visualization of meter etc. You can see a summary of these new features and enhancements here.
New functionality for Scaife also includes addition of services to which users have been long accustomed in Perseus, with support for commentaries been at the top of the list. We are also finishing a long-term backlog of texts for which the structural markup requires some manual intervention(as well as programmatic reformatting).
At the moment we are preparing to sign a contract to replace the Perseus home page and associated data. Our plan is to replace the Word Press platform (which I am currently using) with a different publishing platform, which is much better suited to academic publication. It supports not footnotes, automatically generates citation information and allows us to include interactive visualizations. We will have more to say as soon as the contract is signed.
Our plan is to have more substantive information about what we are doing by the end of the December (i..e., a few weeks after a busy semester starts).
In 1892, at the age of 27, while serving as teacher of Greek at the Packer College Institute, Emily James Smith published translations for selected works of Lucian. She later served as dean (1894-1900) and then trustee (1900-1905) of Barnard College. She provides with readable translations for a number of Lucian’s works. We added the section numbers and attentive readers will note missing sections. Smith chose to leave out those passages that could not be translated in the standards of the time because of their sexual nature.
Her translations have the identifier perseus-eng5 (e.g., tlg0062.tlg029.perseus-eng5 for “the Dream”). She includes both works that have been ascribed to Lucian (with the identifier tlg0061although some are clearly not by him) and two that are labelled as “Pseudo-Lucian” (tlg0061).
tlg0062.tlg029 The Dream
tlg0062.tlg018 Zeus the Tragedian
tlg0062.tlg024 The Sale of Lives
tlg0062.tlg019 The Cock
tlg0062.tlg016 The Ferry
tlg0062.tlg012 A True History
tlg0062.tlg044 Toxaris; Or, Friendship
tlg0061.tlg001 Loukios; Or, the Ass
tlg0061.tlg004 The Halcyon
Henry Watson Fowler (1858-1933) and his younger brother Francis George Watson (1871-1918) are best known for their 1906 publication, the King’s English and the 1926 Modern English Usage, composed by Henry George after the 1918 death of his brother. In 1904, however, the brothers had published The works of Lucian of Samosata, coyly described as “complete with exceptions specified in the preface.” The exceptions included works that did not fit with Victorian sensibilities (such as the Dialogues of the Sex Workers) or that did not match seem worthy of Lucian (as they understood him). They also left out, sadly, On the Syrian Goddess, which Harmon would translate into an archaizing form of English that many contemporary readers would find unbearable.
Nevertheless, the Fowler brothers provide a second translation to complement those by Harmon, Kilburn, Macleod and others. Our goal in Perseus it to work towards providing, as often as possible, two or more translations so that readers can begin to get a sense of how differently the same text can be represented. For now we are adding more translations but we do so in part because new services have emerged (in particularly automatic translation alignment and rich linguistic annotation) that allow readers without knowledge of Greek to begin seeing how the source text and translations are related.
The Fowler translations have the label “perseus-eng4” and their XML source files can be found (where they are available) in Github in the various work directories here.
Another update for our NEH-funded Next Thirty Years of Perseus work. We have now updated Lucian. First, we have fixed issues in the Greek for Lucian works 1-52 as editing by A. H. Harmon. These were originally entered years ago (c. 2010) with a version of Abbyy Finereader that only knew modern Greek. There were some residual OCR errors as well as incorrectly accented words (usually problems because we did not account for enclitics). We also added the textual notes. There were two versions of this Greek up until now but they have been consolidated.
We have also added the corresponding English translations by Harmon. These will all appear in the next upload to the Scaife Viewer, from work 1 (Phalaris) through work 52 (Disowned/Abdicatus)
Translations for all of Lucian are ready to be added, with more than one translation for most of Lucian’s works soon to be available.
Under our new Perseus the Next Thirty Years NEH grant, we have added a set of new translations for Thucydides, including translations in English, French, German, Italian and Latin. These are now available on Github and (with the exception of two German translations of part of Thucydides) can now be viewed in the Scaife Viewer. The opening books of Thucydides in the Zevort translation have been available. We now have the complete translation.
A lot is happening at Perseus. I am writing now to point out the first result from a new NEH grant that formally began one month ago (July 1, 2023). We have released a much revised Greek edition of Philo of Alexandria and a first English translation. The data is available in the First One Thousand Years of Greek Github repository and will find its way onto the Scaife Viewer in its next build.
First, the digital transcription of the Greek text of Philo (based on the Cohn/Wendland Teubner edition). We originally digitized this roughly 10 years ago with the first OCR open source OCR software that we found could manage Ancient Greek. There were issues with this work and we did a major revision. The new files will surely have residual issues and we look forward to finding these but they are a big improvement.
Second, we published the four volume translation that Charles Duke Yonge produced for the Bohn Classical Library in 1855. These are based on the Greek editions that precede the monumental work of Cohn and Wendland. In some cases, Cohn and Wendland reorganized the text and I have adjusted our version of Yonge to follow those changes.
There is a lot more in the pipeline. Our new NEH grant allows us to focus on adding to translations available in Perseus and this is only a first step. Our work with the NEH-funded Beyond Translation project (not to mention a great deal of work on translation alignment by others) has also opened up new possibilities for connecting translation and source texts. These services will begin to appear during the course of the next year.
Development for what would become Perseus began at Harvard in 1985, with our first grant support from an equipment grant provided by Xerox Corporation. David A. Smith created the first initial web version of Perseus at Tufts in 1995. This new NEH grant will be active, and most of our planned development will be completed by 2025, marking thirty years since the first web version of Perseus. Looking to the next thirty years is an ambitious goal, and advances in fields such as AI may lead us to move beyond systems like Perseus. Nevertheless, David Mimno designed the first version of Perseus on which most users depend, Perseus 4.0 (“the Perseus Hopper”), twenty years ago in 2003.
A month ago, I posted about the soft release of an initial version of what we are calling Perseus 6.0. That work will continue through August of this year. Our goals are to finally transition from Perseus 4.0, “the Perseus Hopper.” By the end of summer 2023, we hope that Perseus 6.x will include the remaining key features from Perseus 4.0 (such as support for commentaries and dictionaries) as well as the scalability of Perseus 5.0 (“the Scaife Viewer”) and the new capabilities introduced in Perseus 6.0 (“Beyond Translation”), such as treebanks, aligned translations, metrical visualizations, improved linking from commentaries and lexica, new geospatial visualizations, and integration with IIIF.
This new grant will enable us to build upon the new, more modern codebase and general architecture. We will have more to say about that in the coming months. The bottom line, though, is that as we finish up work on a production version of Perseus 6, we are already in a position to begin planning for Perseus 7 in 2025 or 2026.
Five years after the March 15, 2018, announcement of the Scaife Viewer, we are announcing Beyond Translation, the first version of the sixth generation Perseus (Perseus 6.0). The current NEH-funded phase of work runs through August 2023. We have a great deal of content to add and much to do with every aspect of the system, but the basic features of Perseus 6 are now largely in place.
You can experiment with Beyond Translation directly but it is not yet as transparent as it will (hopefully) become as to what features are available and where those features are available. A more proper splash screen will appear this summer but, in the meantime, we have put up a first draft of information about the new features and how you can get at them. We expect that documentation to evolve as well.
Tufts University will introduce a new course in spring 2023: “Natural Language Processing and the Human Record.” Students at Boston College and Boston University can already cross-register to take this course for credit but, insofar as space allows, it will be open to others in person and to a wider potential audience participating online. This project-based course will not only provide opportunities for students of Greek and Latin, but also for students of other historical languages. It also addresses a major gap between the curricula to which most students of historical languages have access and the realities of doing research in a digital age.
When Princeton, for example, announced a tenure-track job at the rank of Assistant Professor in Ancient Mediterranean Languages and Cultures to begin in Fall 2023, it specifically asked for someone “who can help us expand and diversify our offerings, for example by adding a language to those we already teach, and/or using digital methods and resources, and/or harnessing the insights of linguistics to illuminate broader cultural issues in the study of ancient Greece, Rome, and related ancient and later cultures.”
Language technologies allow students of the Greco-Roman world to address all three of the intellectual goals that this job posting requests. In particular, students of Ancient Greek and Latin who take advantage of contemporary digital methods will be positioned to work with a variety of languages. The figure below illustrates how we can, for example, now offer dense linguistic annotations for a growing number of sources in historical (and contemporary) languages.
Screenshot from the NEH-funded Beyond Translation Project that is building a next generation reading environment for the Perseus Digital Library.
A reading environment such as the one above depends upon a hybrid environment that integrates automated analysis based not only on both machine learning and traditional procedural programming but also on contributions by human experts on the particular source. Knowledge of the language (whether in the form of annotated training data or heuristic rules) provides the starting point for computation and the computation can improve based on expert feedback. We need participants with strengths on both the computational and the content sides (and ideally some participants who can contribute to both sides of this process).
Few programs (if any) are, however, designed to provide students of Greco-Roman culture with the skills that they need to apply digital methods. Those students who do acquire such skills often do so as undergraduates in Computer Science, working in a job involving computation before they begin graduate school, or as something they pick up on the side during graduate school.
In the Tufts Department of Classical Studies, we will be teaching a new course with the title “Natural Language Processing and the Human Record.” It will be taught for the first time in spring 2023 as CLS 191 (and will, in subsequent years, appear with its own number as CLS 162).
This class will be taught on Monday nights from 6:00-8:30 pm so that people who are not regularly on the Tufts campus (such as in-service teachers and students from other local institutions) would be able to participate in person. An existing agreement would allow students from Boston University and Boston College to cross-register, but, if space allows, others are welcome to join. The course is officially listed as in person but we would work to make it accessible remotely as well.
Any intellectually determined student could profitably take this class. First, those who wish to focus on the computational side would need to acquire core skills in programming with Python and in working with Jupyter Notebooks but that is certainly doable, given the variety of online tutorials available, between the end of class in fall 2022 and the beginning of this class. The work required would be non-trivial but effective computational scholarship has long required, and probably long will require, a great deal of informal, on-going, self-directed study.
Second, although ability to apply a range of Python based libraries will always be a big help and extend the intellectual range, students with an interest in how to organize philological data could take this class and focus on topics such as the application and assessment of methods such as morpho-syntactic analysis (particularly the Universal Dependencies Framework), co-reference resolution, translation alignment, named entity recognition and linking, topic modeling, sentiment analysis, and ontology development. Technical terms such as these may be unfamiliar to most practitioners (and do evoke blank stares from most senior scholars), but they represent foundational new building blocks upon which the study of historical languages must be based in a digital age. Early career researchers, as well as students who wish to use their study of the past to prepare them to flourish in the modern world, face very different challenges and opportunities than those who were fashioned by the limitations and assumptions of late print culture.
The course description specifically mentions Ancient Greek and Latin because those are two languages that we know we can support but students are welcome to focus on any language where we have independent expertise to help guide and evaluate their work.
Strong contributions from the course will have an opportunity to be published, with credits for individual authors and/or each member of the team, both in the Tufts Dataverse and (as appropriate) in the new Perseus.
CLS 191 01 Seminar on Current Topics in Digital Humanities: Natural Language Processing and the Human Record Cross listed with GRK 191 01 and LAT 191 01 G. Crane 3 SHU In Person (although we will make remote participation possible0 Mondays, 6:00 – 8:30 pm (local time in Boston, MA, USA)
This class explores the application of natural language processing to the study of the human record and serves two complementary audiences. First, students who are familiar with, or able quickly to develop familiarity with, Python and related technologies can use these skills to develop course projects. Second, students who do not yet have this technical background but who wish to focus on how to publish born-digital versions of historical sources can take his class to develop new ways of reading, organizing and analyzing texts. Students of Greek or Latin who wish to focus on the language can take this class as GRK 191 or LAT 191. Students who wish to focus on another language (including sources in English) are welcome but should consult the instructor. We will cover recent publications and examine current applications that define the state of the art in digital humanities and digital publication. While students will be able to work on their own, we will particularly support the development of collaborative projects in which students with complementary skill sets work together.
Recommendations: CLS 162 – CLS 161, CS 10, CS 11;
For those enrolling in GRK 191 or LAT 191: three or more semesters of study recommended.
Figure 1: lines of Homeric epic that share vocabulary with the opening lines of the Iliad.
This paper announces the creation of a version of the Homeric Iliad and Odyssey that links each line of each poem with those other lines in the Iliad and the Odyssey that share the most significant vocabulary. Each line has at least one parallel. The line with the most parallels (Od. 2.569) has 227 parallels but that is exceptional. The average line has 24.4 parallels. Forty-eight files, one for each book in the Iliad and Odyssey, are available on GitHub and I expect to add them to other repositories in the future. This paper describes how similarity is calculated.
I had created this dataset for the sake of curiosity and I had not intended to publish it. I am publishing this now because, every time I wish to read a passage in Homer carefully, I find myself consulting this hypertextual version of the the poems. I constantly see new connections or simply marvel at the flexibility of Homeric formulaic composition as it reveals itself. I expect that most readers may use this to explore, according to various different approaches, Homeric formulaic composition. The algorithm for ranking lines, known by the abbreviation tf/idf, is (as I will explain) both venerable (not considered a good thing in computer science) and simple.
There are other ways by which to find patterns of traditional composition in Homeric poetry. Each method is quite tractable, given the openly licensed data that we have at our disposal about Homeric epic.
Word embeddings: Word embeddings are a relatively recent technique, made possible by advances in machine learning that have been, in turn, made possible by advances in computing hardware. Essentially, word embeddings can provide the context for particular words to identify related terms (e.g., “rock” and “stone” are similar in meaning). The most recent strategies can capture word senses (e.g., distinguish contexts were the English term “bank” designates a financial institution vs. the side of a river). Word embeddings work best when we have much larger collections than Homeric epic but we could probably make up for lack of data by using the Perseus Treebanks to show which words depend on which and in what function. Embeddings may allow us to measure the degree to which different words are actually synonymous and only appear as different options because they allow the tradition to express an identical idea in different metrical slots of the hexameter.
Collocations: We can measure the extent to which two or more words co-occuring exceeds random chance. This method can allow us to identify significant phrases (e.g., “Peleides Achilles”) even when those phrases are composed of very common words.
Metrical position: We can examine the tendencies of particular words to appear in one or more metrical slots in the line (as has Sansom 2021). If a word is not only in two different lines but in the same metrical position, we can increase the weight that we assign to that shared similarity.
The first and second halves of lines: Repeated phrases tend to cluster before or after the caesura (the main break that divides virtually every Homeric hexameter into two pars) and it would make sense to compare the first and second halves of lines. Anyone looking at this dataset will see, over and over, cases where two lines with relatively modest similarity scores have identical first or second halves (especially when the shared words are themselves common individually).
Each of the techniques above could retrieve more clearly formulaic expressions. In the terms of information retrieval, this would improve the precision, i.e., reducing false positives but at the expense of missing some valid results. Using tf/idf to compare whole lines sacrifices precision to find potentially interesting collocations, turning up related lines that more demanding algorithms would miss. The more general method also reveals the fuzzy line between formulaic composition and the semantics of language.
Consider, for example, the lines most similar to Od. 5.409:
Od. 5.409
Ζεύς , καὶ δὴ τόδελαῖτμα διατμήξας ἐπέρησα ,
… and indeed, I have cut my way through and crossed this gulf,
Od. 7.276
νηχόμενος τόδε λαῖτμα διέτμαγον , ὄφρα με γαίῃ
by swimming I cut my way through this gulf …
Od. 5.174
ἥ με κέλεαι σχεδίῃ περάαν μέγα λαῖτμα θαλάσσης ,
[you, Calypso] who urge me to cross the great gulf of the sea.
The variation τόδελαῖτμα διατμήξας/διέτμαγον, of course, illustrates a single formula that starts in the same slot but varies in the number of subsequent slots it occupies (˘˘| ˉ˘˘ |ˉˉ|ˉ vs. ˘˘ |ˉ˘˘ |ˉ˘˘). What particularly caught my eye was the fact that linking these three lines immediately answered a question that I had in my own mind as a reader. What verb governs λαῖτμα? The translation above (adapted from A. T. Murray’s Loeb edition) takes the noun with both verbs. The two linked lines immediately support this decision. The comparanda are there in front of me as I read. The form διατμήξας may well most directly govern the noun λαῖτμα, but surely the Greek audience would understand that both verbs governed λαῖτμα.
If I want to understand the semantics of the verb peraô, “to cross,” I need to consider the fact that this verb governs the noun laitma, “gulf,” not only in Od. 5.174 but also, at least indirectly, at Od. 5.409. As a side note, this also highlights a fundamental weakness of the Perseus Treebanks – and, indeed, of the use of trees to represent syntax. Trees are a class of graphs in which each node can have one, and only one, ancestor. We cannot have a single word depend on two other words if we use a tree. We can, of course, augment what we store with the tree by adding another layer of annotation easily enough — anyone working with linguistic annotation will have multiple layers of annotation. But the fact is none of the Greek and Latin Treebanks with which I am familiar have added such a layer. On the other hand, our print reference works are often no better: Cunliffe’s Homeric Lexicon notes that perâo governs laitma in Od. 5.174 but does not mention its connection to laitma in Od. 5.409.
It would — and will ultimately — be easy to build an exploratory environment in which readers can modify the parameters to suit their needs and choose among the various linking techniques that I listed above. Such interactive environments are, however, difficult to maintain over time — there is, in fact, no way to be confident that any piece of code will function decades or generations from now. Modern scholarship on Homeric poetry goes back at least to Friedrich Wolf’s 1795 Prolegomena ad Homerum. In my own case, I have (to take three examples that happen to come to mind) recently looked at scholarship about Homeric scholarship published in 1872 (Düntzer), 1928 (Parry), and 1968 (Hainsworth) — even those three works represent a span of nearly one century and extend back more than half a century from the present. If I am consulting scholarship published a century and a half ago, what can I do to maximize the chance that my contributions would be useful in a century and a half?
It may well be more likely than not that the field changes so much that contemporary articles and monographs play little role in the future study of Homeric epic. Nevertheless, we still participate in a conversation that extends over decades, generations and centuries. We should, I believe, do what we can to maximize the survivability of what we do. To do so, I have chosen the following:
Open license: By publishing under an open license, I make it possible for others to make and preserve copies of what I produce. The more use this work finds, the more copies will be made and the better the chances that at least one will survive.
Publication in long term repositories. The most widely used repository for Digital Philology is surely GitHub but GitHub is a corporate project and no one can be sure of its future (although it is likely that a successor platform would take on content in the future if GitHub falters). We also deposit the results in the Tufts University Digital Collections and Archive, which is tasked with long term preservation, and the European Zenodo archive.
Very basic formatting. The tables, pictures, and paragraphs in this description should be supportable for the foreseeable future.
A tab-delimited file as data format. The core results of this work are published in tab-delimited files that should be easily understood. The technical terms tf/idf and edit distance (described below) are not currently well understood among students of Greek and Latin but they are very basic concepts from computer science and readers should be able to learn what they mean even without the narrative explanation offered here. Otherwise, the data includes citations to, and accompanying lines from, the Homeric epics with a list of dictionary entries (lexemes) that each line pair share.
The work described here depends upon two data sources. First, machine readable versions of the Iliad and Odyssey as edited by T. W. Allen more than a century ago (Allen 1920) provides the starting point for this work. Second, the Perseus Dependency Treebank Project used this text to create a linguistically annotated edition of the two epics, that includes part of speech, syntactic function, and a lexeme (the dictionary form) for each inflected form of the two epics. In this analysis, we want to capture different inflected forms of the same word because Homeric formulaic composition will change the form to suit the syntactic needs of the moment. We look for shared lexemes in different lines. The more shared lexemes, the higher the similarity score for any two lines. The tf/idf metric allows us to dampen the weight given to more common lexemes and emphasize less common lexemes.
Anyone with a list of mapping from the inflected forms in Homeric poetry to lexemes could apply this method. Results will differ, though probably not in ways that are significant for most readers of Homeric epic. Different lexica differ slightly in how they map forms to lexica — some lump very different word senses under a single lexeme, others split a forms into two different lexemes. Some editions choose different readings. In an ideal world, we would include variant readings and/or different critical editions — this would be particularly useful for those who are interested in different variants and see the Homeric epics as dynamic parts of a living tradition (multitexts, on which, see the Homer Multitext Project). Results would thus vary based on different schemes of lemmatization and different editions. Those studying Homeric epic as a multitext should create a version of this work that includes a range of different readings. The results published with only a single version of the text, however, already demonstrate the flexibility of Homeric formulaic composition.
After assigning a score to the shared vocabulary in each line of the Iliad and the Odyssey, the algorithm sorts the most highly scored lines first and then prints out the results until the similarity score drops below a preset cutoff point. Each output line contains the following eight tab-delimited fields.
index: Each line of the Iliad and Odyssey is paired with at least one other line based on shared vocabulary.
base citation: An abbreviated version of the citation of the current line that is being compared to every other line in the Iliad and Odyssey. Citations that begin “12-1:” are from the Iliad and “12-2:” from the Odyssey (this follows the convention that the original Thesaurus Linguae Graecae (TLG) established giving Homer the serial number 12 and the Iliad and Odyssey 1 and 2 respectively). Book and line numbers are padded with extra zeroes so that users can easily sort them in a spreadsheet. Otherwise, we would jump from “12-1:1.1” to “12-1:10.1,” with book 2 only showing up after we had completed book 19. Thus, we use “12-1:01.001,” rather than “12-1:1.1”.
base line: the text of the line that the system is comparing to all other lines of the Iliad and the Odyssey.
tf/idf: This figure, rounded to one decimal point, provides a score for the similarity between base line and the line to which it is compared. More extensive discussion follows in a separate section. The key point is that tf/idf provides a way to give more weight to less common words and less to more common words — we do not want to give kai, “and,” the same weight as less common terms when we compare the similarity of two lines of Homer.
Edit Distance: This figure quantifies the similarity of two lines by measuring how many operations it would take to convert one line into the other. We use a standard Python to compute edit distance and the score varies from 0 (for completely different strings) to 100 (for strings that are identical. Very high values for edit distance can pick up small editorial changes that might otherwise not be noticed. Thus, the edit distance between the following lines is 99, rather than 100:
In his edition of the Iliad (3rd edition 1920), T. W. Allen used the simple form onomaze, “she called him by name.” In his edition of the Odyssey (2nd edition, 1917), Allen chose to add the “nu-movable,” an extra consonant that can be added to the end of some forms to keep a short vowel from being elided before another vowel. The “nu-movable” has no effect on the meaning — and is irrelevant at the end of the line. The difference is small but could matter if researchers were studying linguistic usage. In this particular detail, the two editions are simply inconsistent. I only noticed the difference because the edit distance was 99 rather than 100 and I noticed the variation. There will surely be other places where a score just below 100 will reveal more significant changes.
Comparison citation and comparison line: These designate the citation and text of the line that is being compared to the base text line.
Lexemes: This lists shared dictionary words (lexemes) and provides information about their relative weight. Achilles, for example, shows up 382 lines in Homeric Epic and its tf/idf weight is 4.28, while common Peleides, which appears in 59 separate lines, has a tf/idf weight 6.15, a higher value than that assigned to Achilles because it is substantially less common. Both Achilles and Peleides appear once in both lines.
Deciding which lines to link:tf/idf
The tf/idf metric is, by computational standards, a very old method: the British Computer Scientist, Karen Spärck Jones (1935-2007) published the algorithm in 1972, fifty years ago as I write this. Nevertheless, this measure remains widely used and provides a simple mechanism by which to compare search for a query in a collection of documents.
In the case of the work described here, an algorithm uses the normalized dictionary forms for each word in each line of the Iliad and the Odyssey as a query, follows the tf/idf metric to determine the similarity of this query line against every other line in the two poems, and then returns a list with the most highly scored lines at the top. If our query contains a word such as de, the word that shows up in the most lines of Homeric Epic (12,138), we do not want to return all the other 12,137 lines. So we assign a cutoff score (rather arbitrarily set at 10 for now). Every time we return a line, we check to see if we have dropped below the cutoff score. If so, we end the list. We return one entry before checking the cutoff score because we want to have at least one example for each line in the Iliad and the Odyssey.
The lines that have the least similarity to the rest of Homeric Epic both appear in the catalogue of ships:
Il. 2.561
Τροιζῆν’ Ἠϊόνας τε καὶ ἀμπελόεντ’ Ἐπίδαυρον
Troezen and Eïonae and vine-clad Epidaurus,
Il. 2.656
Λίνδον Ἰηλυσόν τε καὶ ἀργινόεντα Κάμειρον,
Lindos and Ialysus and Cameirus, white with chalk.
The only words that these two lines share with any other lines in the Iliad and Odyssey are the connectors te and kai, which together are conventionally translated “both and.” These lines are both equally similar to every other line in the Iliad and Odyssey that have this common combination.
The two lines above also demonstrate another point: different methods detect different kinds of patterns. Readers familiar with Homeric formulaic composition will, of course, immediately see that the two lines above are very similar in form and clearly share much the same formulaic pattern. Each line contains, besides the connectors, only proper names and none of the proper names (surprisingly) shows up elsewhere in the epic poems. The two lines least similar to the rest of the epic poems when that similarity is measured by vocabulary are almost identical in terms of formulaic structure. The Perseus Treebanks do allow us to search for similarity based on the parts of speech or the syntactic labels and dependencies in each line. The work described here focuses strictly on vocabulary.
The expression tf/idf contains two acronyms: term frequency (tf) and inverse document frequency (idf). The measure assumes that we have a collection broken up into documents. Documents can, in turn, be journal articles, news stories, or chapters of a book. But documents can also be individual sentences — or, as in the case of the work described here, individual lines of poetry.
When we compare two lines, we want to give more weight to a word such as mênis (which is conventionally translated as “wrath” or “anger and which appears in 16 lines of Homeric poetry) than we do to the connector de (which is roughly equivalent to “and” and shows up in 12,138 lines), while occurrences of the name Achilles (which shows up in 382 lines) should be somewhere in between. The tf/idf metric yields weights of 0.92, 4.28, and 7.45 for de, Achilles, and mênis respectively. We calculate the similarity of two lines by adding the tf/idf values for each shared dictionary entry. Consider the opening line of the Odyssey and its closest match, which comes from the Catalogue of Ships in the Iliad.
Each word is accompanied by the number of different lines of the Iliad and the Odyssey in which it occurs, the corresponding tf/idf score based on that frequency, and then number of times it appears in both lines (i.e., if it occurs 2x in one line and 3x in the other, we count it as 2x). If we add the tf/idf scores for egô (“I'”), enepô (“to utter”) and Mousa (“Muse”), we get a score of 16.3 (rounded to one digit).
Traditionally, tf/idf is applied to collections where the documents are long enough that the word frequency within documents matters. Consider a collection of 100 newspaper articles in which two words appear 20 times. The first of these words may be a typical, medium frequency word such as “president” that could apply to a number of figures while the other may be more tightly bound to a particular topic (“Macron”) and cluster in two or three documents. The tf/idf measure is designed to capture the fact that, in such a case, “Macron” tells us more about a document than does “president,” even though each appears the same number of times in the corpus.
Lines of Homer are much shorter than newspaper articles. At one extreme, 4 lines contain only 3 words: ranging from 3 words (4x: Il. 2.706, 11.427, Od. 10.137:
Il. 2.706
αὐτοκασίγνητος μεγαθύμου Πρωτεσιλάου
Il. 11.427
αὐτοκασίγνητον εὐηφενέος Σώκοιο
Od. 10.137
αὐτοκασιγνήτη ὀλοόφρονος Αἰήταο·
Il .15.679
κολλητὸν βλήτροισι δυωκαιεικοσίπηχυ
Three begin with with forms of αὐτοκασίγνητος. The fourth, 15.678, contains a single token that contains four distinct words (δυωκαιεικοσίπηχυ including kai, “and”).
On the long end, the treebank counts 13 tokens in only two lines, and in each case that count is two words higher than most would list because, in adding syntactic annotation, we split οὔτε into οὔ τε.
The other two lines are both variations on a formula that begins ἂψ δʼ ὅ γʼ ἐπʼ οὐδὸν ἰὼν κατʼ ἄρʼ ἕζετο. The second occurs relatively quickly after the first (a gap of 250 lines, < 1% of the 27,000 lines of Homeric poetry).
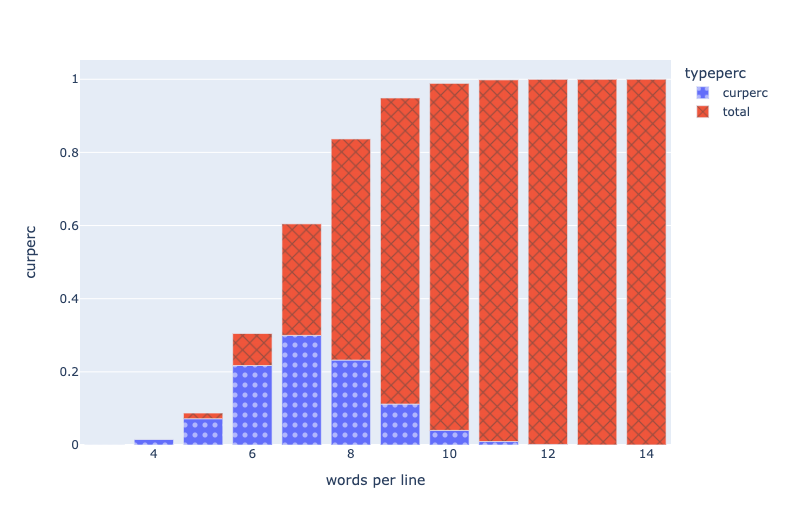
Three quarters of all lines are 6, 7, or 8 words long (22%, 30%, and 23% respectively). Almost 99% are 4 to 10 words long.
words/line
lines
%
tot %
3
4
0.01
0.01
4
430
1.55
1.56
5
1996
7.18
8.74
6
6042
21.74
30.48
7
8331
29.98
60.46
8
6454
23.22
83.68
9
3112
11.20
94.88
10
1111
4.00
98.88
11
264
0.95
99.83
12
43
0.15
99.98
13
2
0.01
99.99
14
3
0.01
100.00
The tight clustering of line lengths stands out from bar chart.
Figure SLEN: There are sentences with 3, 12, 13, and 14 words.
Sentences with 3, 12, 13 and 14 words are so few in number that they are not even visible in the figure above.
Such lines obviously contain many fewer words than documents such as even short news articles and most words will only occur once in a line. Nevertheless, of the 27,793 lines in the Allen edition of the Homeric Epics used by the Perseus Treebanks, 3,989 (14%) have two or more instances of the same lexeme. The majority of these lexemes are, however, very high frequency words.
lexeme
in lines 2+x
in lines 1+x
1
δέ
1055
12138
2
τε
907
4322
3
ὁ
308
5870
4
καί
262
5283
5
οὐ
246
2695
6
ἤ
139
729
7
ἐγώ
123
2871
8
σύ
99
1900
9
εἰμί
49
2118
10
ἄν
43
1449
The three connectors, de (which is the neutral particle indicating a new sentence) and te, and kai (which are often equivalent to “and”) account for more than 2,000 lines — more than half of all duplicates. Such repetitions are very useful but it is not clear that the line linking strategy described here is the most useful way to study such syntactic repetition. The tf/idf measure is most fully effective when documents are relatively consistent in size (as the lines of Homer are) but the lines are so short that most repetitions involves function words rather than content. The repetition of function words can reveal syntactic patterns (especially when we combine them with metrical information and with syntactic data from the treebank) but repetition of words within a line usually does not tell us much about shared semantic content.
There are, however, cases where repetition captures formulaic repetition across lines.
Il. 2.489 appears during the dramatic opening to the Catalog of Ships The poet is describing various limitations (including not having enough tongues and mouths) that make it impossible to describe the combatants at Troy. Il 23.851, by contrast, lists the prize that Achilles sets for the contest in archery.
The two lines above clearly share the same formulaic pattern with five words starting in identical metrical slots but the differing syntactic structure clearly brings out the flexibility of Homeric formulaic composition. In Il. 2.489, the tongues and mouths are the subjects of the verb eien, a form of the verb “to be,” and this verb appears at the end of the line. In Il. 23.851, the ten double-axes and ten single-axes are the objects of the main verb, tithei, “he set down” (taking κὰδ, “down,” as modifying the verb).
Two of the three shared lexemes, the connector de and the particle men have very little weight.
found in lines of Homer
Weight
Shared frequency
δέ
12138
0.92
1
μέν
1872
2.699
1
δέκα
20
7.342
2
The repetition of deka doubles its weight to 14.684 — more than enough for the line to exceed the cutoff score of 10.
Likewise, in the following example, the repetition of heneka, “because of”:
Il. 3.100
εἵνεκ‘ ἐμῆς ἔριδος καὶἈλεξάνδρουἕνεκ‘ ἀρχῆς·
because of my quarrel andbecause of the beginning of Alexandros
Il. 6.356
εἵνεκ‘ ἐμεῖο κυνὸς καὶ Ἀλεξάνδρουἕνεκ‘ ἄτης,
because of me, the bitch, and because of the madness of Alexandros
Each instance of heneka adds 5.733 to the score — the single repetition is enough by itself to create a link between the two lines. The two lines are clearly variations on one another. First, we can point out that the choice of two different forms of the preposition, heineka and then heneka, allows the same word to fill two differently shaped metrical slots (long-short in the first case, short-short in the second).
Second, each line is slightly different in meaning and even in structure. In Il. 3.100, Menelaus is speaking to the Greek and arguing that a proposed one-on-one combat should be between himself and Alexandros. He refers to “my quarrel,” because the war is ostensibly being fought to return Helen. The form emês is a possessive adjective that means “my.” The line ends with the word archês, “beginning,” because it was the Alexandros who began the war.
In Il. 6.356, Helen is speaking to Hector on his visit to Troy. She speaks of herself and of Alexandros is very harsh terms because they are responsible for the war. She, however, uses emeio, a genitive form of the first person pronoun (rather than the adjective “my”). The phrase means “of me, the dog” (properly translated by English “bitch”). Here the noun kunos, modifies emeio whereas in the earlier line emês, “my,” modifies eridos, “quarrel.” And Helen refers to the “idiocy” (atês) rather than simply the more matter-of-fact “beginning” of Alexandros that has caused the war. The information conveyed in the two lines differs somewhat. The second variation is far sharpe, even brutal. This offers an excellent example of Homeric traditional composition.
I have, as I will describe below, found this format useful for tasks such as computing similarities among different books of the Iliad and the Odyssey and for tracking the varying degree to which different lines in different parts of the epics share more or less vocabulary. I try to avoid stating that lines with fewer attested parallels are not formulaic and to point out, rather, the extent to which we can observe parallels in the 200,000 words of our Iliad and Odyssey.
Using the files
Each file contains one book of the Iliad or the Odyssey. Readers can simply scroll through and examine the parallels for each line. I use these files as a kind of dynamically generated commentary. Whenever I read a passage closely, I look to see how many — or how few — linked lines there are and what the parallels reveal.
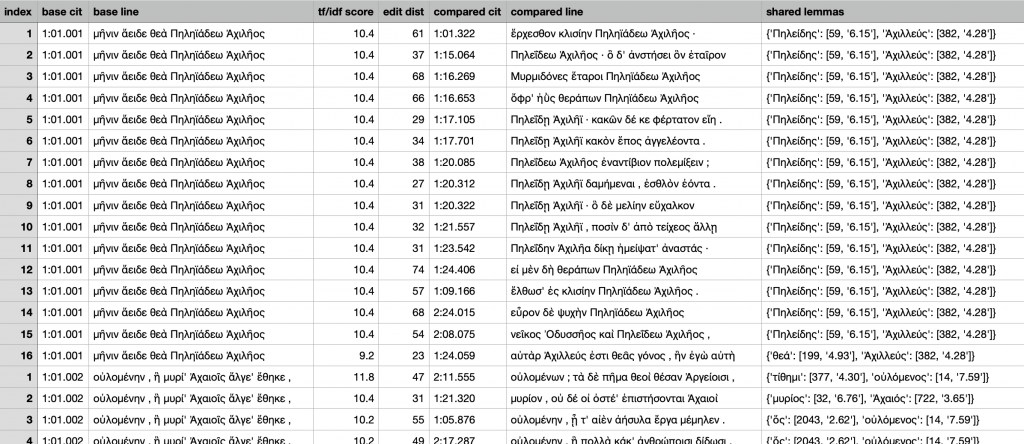
Il. 1.1
μῆνιν ἄειδε θεὰ Πηληϊάδεω Ἀχιλῆος
Sing, goddess, the wrath of Achilles, son of Peleus,
The first line of the Iliad shares two lexemes with sixteen other lines of Homeric epic. To make the exposition clearer, I have optimized the list below a bit. I don’t present all the information that each line in the data set includes. I have highlighted the shared lines. I have also resorted the results to make the word order and different spellings stand out. The changes only make more noticeable patterns that a careful viewer would quickly detect.
Il. 24.406
εἰ μὲν δὴ θεράπων Πηληϊάδεω Ἀχιλῆος
Il. 16.269
Μυρμιδόνες ἕταροι Πηληϊάδεω Ἀχιλῆος
Od. 24.15
εὗρον δὲ ψυχὴν Πηληϊάδεω Ἀχιλῆος
Il. 16.653
ὄφρ’ ἠῢς θεράπων Πηληϊάδεω Ἀχιλῆος
Il. 1.322
ἔρχεσθον κλισίην Πηληϊάδεω Ἀχιλῆος·
Il. 9.166
ἔλθωσ’ ἐς κλισίην Πηληϊάδεω Ἀχιλῆος.
Od. 8.75
νεῖκος Ὀδυσσῆος καὶ Πηλεΐδεω Ἀχιλῆος,
Il. 20.85
Πηλεΐδεω Ἀχιλῆος ἐναντίβιον πολεμίξειν;
Il. 15.64
Πηλεΐδεω Ἀχιλῆος· ὃ δ’ ἀνστήσει ὃν ἑταῖρον
Il. 23.542
Πηλεΐδην Ἀχιλῆα δίκῃ ἠμείψατ’ ἀναστάς·
Il. 21.557
Πηλεΐδῃ Ἀχιλῆϊ, ποσὶν δ’ ἀπὸ τείχεος ἄλλῃ
Il. 20.322
Πηλεΐδῃ Ἀχιλῆϊ· ὃ δὲ μελίην εὔχαλκον
Il. 17.105
Πηλεΐδῃ Ἀχιλῆϊ· κακῶν δέ κε φέρτατον εἴη.
Il. 17.701
Πηλεΐδῃ Ἀχιλῆϊ κακὸν ἔπος ἀγγελέοντα.
Il. 20.312
Πηλεΐδῃ Ἀχιλῆϊ δαμήμεναι, ἐσθλὸν ἐόντα.
Il. 24.59
αὐτὰρ Ἀχιλλεύς ἐστι θεᾶς γόνος , ἣν ἐγὼ αὐτὴ
The last line in the long list above would probably be considered noise to someone exploring the workings of formulaic poetry. Achilles shows up in both but the other shared word, theâ, “goddess,” refers to the Muse in Il. 1.1 and to Achilles’ mother, Thetis, in Il. 24.59. Observers with no knowledge of Greek would see this if they consulted the translations. All readers, whether they know Greek or not, would, of course, have to understand the context of Il. 1.1 and Il. 24.59 and thus to conclude that the pairing of Il. 1.1 and Il. 24.59 probably reflects a random collocation.
But even this line reveals an important feature of the formulaic system: in this, the last of sixteen examples, the name Achilles is spelled, for the first time, with two lambdas (-λλ- vs. -λ-). Homeric tradition exploits the ability to alter the spelling because the -i- in the name Achilles is short (in Greek, the letters a, i, and u can be long or short) but by doubling the following lambda, the short syllable is lengthened. The tradition offers two spellings for Achilles and the name can thus fit into different metrical slots in the line.
Most observers, with or without knowledge of ancient Greek, would immediately see the dominant feature of “Achilles the son of Peleus”: this pair of words always appears either at end or the beginning of a line.
Readers who look closer will notice that the words are not spelled identically. Ancient Greek is highly inflected and we have the same formula not only in different positions (line beginning and end) but also in different cases: genitive (PêlêiadeôAchilêos, “of Achilles the son of Peleus”), accusative (Pêlêiadên Achilêa, “Achilles the son of Peleus as the object of a verb), and dative (Pêlêiadêi Achilêi, “to/for Achilles the son of Peleus). But even without knowing the details of the case system, we can see that there are both continuities and variations in this same formulaic expression.
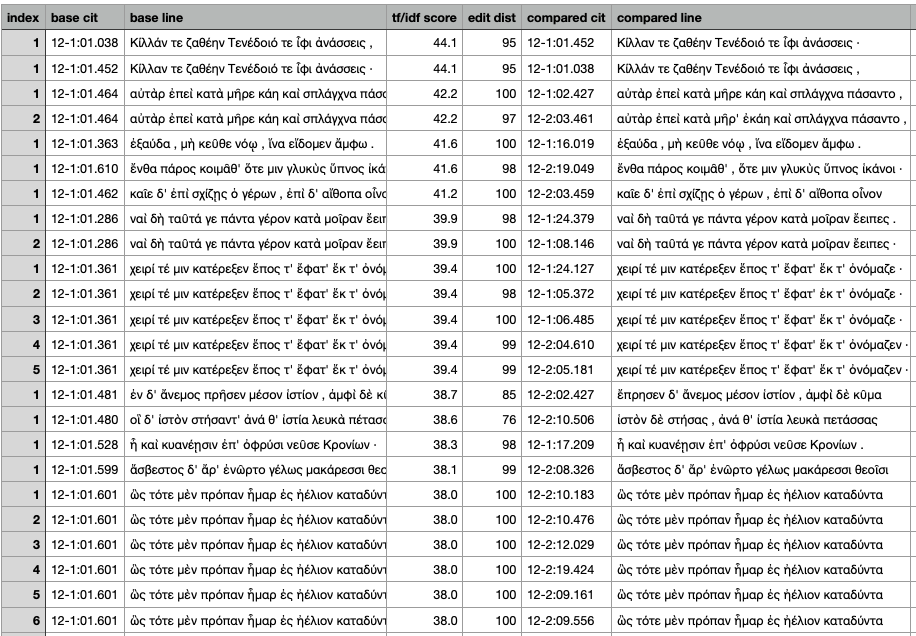
The tab delimited files can easily be loaded into a spreadsheet and resorted. You could, for example, look at those lines of Iliad 1 (for example) that have the highest similarity scores. This will identify lines with identical vocabulary, with the least common shared vocabulary generating this highest scores.
Figure 2: The lines of Iliad 1 with the highest similarity scores to other lines in Homeric epic.
Lines that are not quite identical but that share less common vocabulary will sometimes score higher than identical lines with common lexemes (e.g., Il. 1.481 and Il. 1.480).
I cited the two lines that share the lowest similarity score to the rest of Homeric epic above. The lines with the highest similarity score in Homeric epic both have scores of 49.8:
Il. 1.2.471
ὥρῃ ἐν εἰαρινῇ ὅτε τε γλάγος ἄγγεα δεύει,
Il. 16.643
ὥρῃ ἐν εἰαρινῇ, ὅτε τε γλάγος ἄγγεα δεύει·
Il. 6.511
ῥίμφά ἑ γοῦνα φέρει μετά τ’ ἤθεα καὶ νομὸν ἵππων·
Il. 15.268
ῥίμφά ἑ γοῦνα φέρει μετά τ’ ἤθεα καὶ νομὸν ἵππων·
I also published two files with summary data. The first, booktots.tsv, publishes the average number of linked lines for each book of the Iliad and the Odyssey.
work:book
links/line
12-1:01
26.2291325695581
12-1:02
19.608893956670500
12-1:03
23.99349240780910
12-1:04
23.095588235294100
12-1:05
24.24312431243120
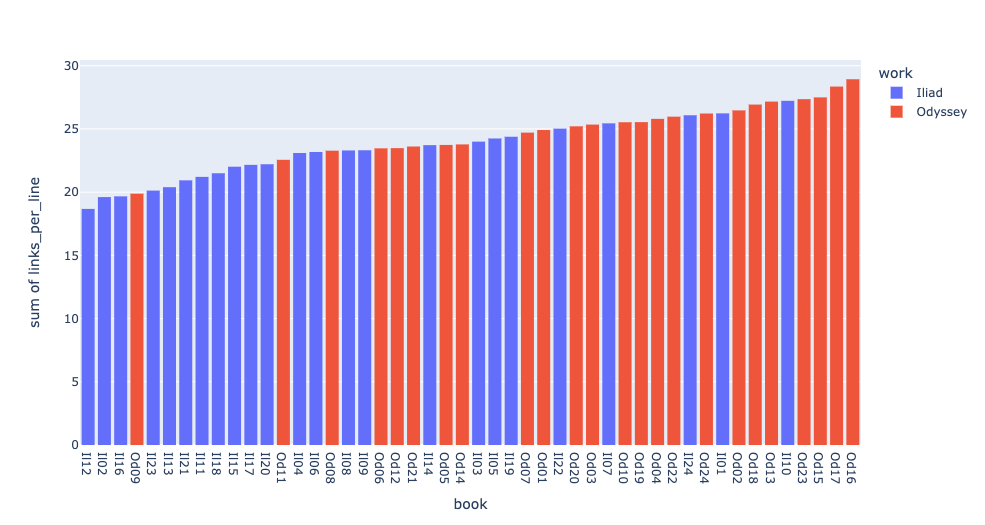
More linked lines reflects more attested repetition and says something about the visibly formulaic nature of each book. I add a graph that illustrates which books of the Iliad and the Odyssey have the most links per line. The range is quite wide — from under 19 links per line in Iliad 12 to almost 29 links per line in Odyssey 16. A range of 50% strikes me as large and surprising.
Figure 3: number of links per line for each book of the Iliad and the Odyssey
The figure reveals several features. First, there is more attested repetition in the Odyssey than in the Iliad — a much bigger difference than I would have expected (although some who see the Odyssey as derivative from the Iliad may claim not to be surprised). Second, the book of the Odyssey with the least attested repetition is book 9, which tells the story of Polyphemus. That suggests to me that this story draws from traditions that are unusually distinct from the rest of the Odyssey. Third, the book of the Iliad with the most repetition is Iliad 10 — which many have seen as both an outlier and as more Odyssean. Dué and Hackney (2010) have made strong arguments that Iliad 10 stands out because it draws on traditions of ambush that are not widely attested elsewhere in the Iliad and Odyssey and that that distinctive content makes this book appear as an outlier. Their argument makes the fact that Iliad 10 has by far the most attested repetitions of any book in the Iliad all the more striking.
Second, I include a file measuring how many linked lines connect each book in the Iliad and the Odyssey with each other. I have added the number of shared words in all linked lines for any two books and, to make up for the fact that different books vary so much in size, then divided by the sum of the number of lines in the two books combined. Each book then has a number ranking its closeness to the other 47 books. There is more to be done here but I think that the preliminary data is worth sharing. It is available as book2book.tsv. The following are the 10 links that, by this metric, have the lowest scores and thus are least similar.
source
srcwords
target
targwords
nlinks
links_per_word
12-1:12
3777
12-2:07
2910
3462
0.5177209510991480
12-2:07
2910
12-1:12
3777
3926
0.5871093165844180
12-1:12
3777
12-2:06
2890
5566
0.8348582570871460
12-2:06
2890
12-1:12
3777
5793
0.8689065546722660
12-1:16
7002
12-2:06
2890
8710
0.8805095026283870
12-1:12
3777
12-2:23
3231
6306
0.8998287671232880
12-2:06
2890
12-1:16
7002
9029
0.9127577840679340
12-1:17
6181
12-2:07
2910
8379
0.9216807831921680
12-1:12
3777
12-2:14
4623
7775
0.9255952380952380
12-1:12
3777
12-2:03
4274
7514
0.9333002111538940
Iliad 12 and Odyssey 7 have the least in common. Note that the score from Iliad 12 to Odyssey 7 is not quite the same as going from Odyssey 7 to Iliad 12. That results from the way we manage uncommon lines but the variation is not large.
The most closely connected books follows:
source
srcwords
target
targwords
nlinks
links_per_word
12-2:17
5319
12-2:16
4187
58336
6.136755733221120
12-2:19
5230
12-2:17
5319
64059
6.072518722153760
12-2:16
4187
12-2:17
5319
57720
6.071954555017880
12-2:17
5319
12-2:19
5230
63286
5.999241634278130
12-2:11
5444
12-2:10
4983
59526
5.708832837824880
12-2:10
4983
12-2:11
5444
59023
5.660592692049490
12-2:17
5319
12-2:15
4811
53620
5.293188548864760
12-2:04
7326
12-2:17
5319
66699
5.274733096085410
12-2:04
7326
12-2:15
4811
63941
5.268270577572710
12-2:16
4187
12-2:15
4811
47263
5.252611691487000
Odyssey 16 and 17 are the most similar books by this metric and Odyssey books are more like each other than Iliad books are. That may reflect the fact that the Odyssey does not need a stream of otherwise unknown figures who appear only to die in battle at the hands of better known heroes. But I suspect that it says something about the composition of the Odyssey.
The full file contains 2256 different links and others can compare them at greater length.
Hainsworth, J. B (1968). The Flexibility of the Homeric Formula. Clarendon P., 1968, https://catalog.hathitrust.org/Record/001223030.
Parry, Milman (1928). “L’Épithète Traditionnelle dans Homère: Essai sur un problème de style Homérique.” The Center for Hellenic Studies, 1928, https://chs.harvard.edu/book/parry-milman-lepithete-traditionnelle-dans-homere-essai-sur-un-probleme-de-style-homerique/.
Parry, Milman (1928b). “Les formules et la métrique d’Homère.” The Center for Hellenic Studies, https://chs.harvard.edu/book/parry-milman-les-formules-et-la-metrique-dhomere/.
Sansom, Stephen A. “Sedes as Style in Greek Hexameter: A Computational Approach.” TAPA (Society for Classical Studies), vol. 151, no. 2, 2021, pp. 439–467, https://doi.org/10.1353/apa.2021.0017.
Spärck Jones, K. (1972). “A Statistical Interpretation of Term Specificity and Its Application in Retrieval”. Journal of Documentation. 28: 11–21.