Sample Project
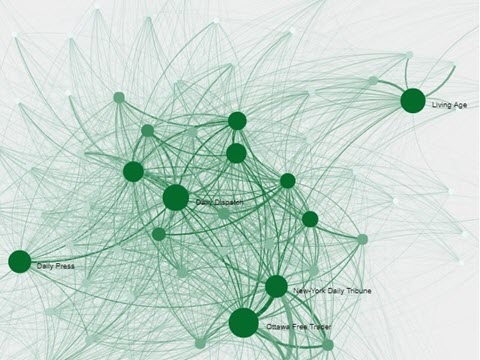
Viral Texts Project, by Ryan Cordell et al.
The Viral Texts project examines pre-Civil War newspapers in America to see what made texts “go viral,” or get reprinted, throughout the century. This visualization shows shared reprints of in newspapers from 1836-1860.
Readings
Sample Data Sets
- Project Gutenberg
- Google Books
- Hathi Trust (Hathi Download Helper)
- NLP-Ready texts
- Early Modern Texts Datasets
- List of Tufts-accessible collections of texts
- OPUS – the open parallel corpus
- Sketch Engine
Tools
- Voyant Tools – word frequencies, concordance, word clouds, visualizations
- TAPorWare – directory of data cleaning, annotating, and analysis tools
- Lexos – easy web based tool for visualizing text files, includes clickable preprocessing settings